Business · Hiring
How to Hire a DevOps Engineer in 2026: Kubernetes, IaC, and the Roles That Replaced DevOps
The 'DevOps engineer' title now covers three distinct jobs: platform engineer, SRE, and CI/CD specialist. Here's what each role actually does, what to screen for, and what the market pays.

Prathviraj Singh
6 min read

Sponsored
When a startup says they need a “DevOps engineer,” they usually mean the person who will set up their CI/CD pipeline, manage Kubernetes, write Terraform, handle cloud costs, and be on call when the site goes down. That is four different jobs, and the market has mostly sorted out that they are not the same job.
Before you post a DevOps role, decide which of these you actually need.
The three jobs hiding inside “DevOps”
Platform engineer. Builds and maintains the internal developer platform: Kubernetes clusters, service templates, CI/CD abstractions, developer tooling, deployment frameworks. The customer is other engineers, and the goal is making them faster and more self-sufficient. This role cares deeply about developer experience. If your engineers spend significant time fighting infrastructure or wait 20 minutes for CI to finish, a platform engineer is what you need.
Site reliability engineer (SRE). Owns availability, latency, and production reliability. Writes runbooks. Manages SLOs and error budgets. Conducts postmortems. On call in a structured way. Tends to have more software engineering background than classic ops. The SRE model, as defined by Google’s original book, treats reliability as a software problem. If your team ships features but nobody owns reliability, this is the gap.
CI/CD and toolchain specialist. Builds and maintains the pipeline: GitHub Actions, ArgoCD, GitLab CI, build caching, artifact management, deployment automation. Overlaps heavily with platform engineering but can be narrower. This is often the first DevOps hire at an early startup.
Most “DevOps engineer” job descriptions mix all three. The best hire for an early-stage team is someone who can do all three at a junior or mid level. At a 50+ engineer company, you need specialists, and posting a generalist role will attract the wrong candidates.
What the stack looks like in 2026
Any serious DevOps hire in 2026 needs to be fluent in:
Containers and Kubernetes. Docker is assumed. Kubernetes is now the default for everything above “small app deployed on a single server.” The real question is not “do you know Kubernetes?” but “have you operated it in production under load?”
Infrastructure as Code. Terraform or OpenTofu is the most common choice. AWS CDK is strong for AWS-only teams. Pulumi is used in teams that want TypeScript or Python over HCL. The tool matters less than whether they write IaC like software: modules, state management, code reviews, testing with Terratest or Checkov.
CI/CD. GitHub Actions is dominant. GitLab CI is common in enterprise. ArgoCD or Flux for GitOps deployment to Kubernetes. The candidate should have opinions about when GitOps patterns help and when they add complexity that small teams don’t need.
Observability. OpenTelemetry for instrumentation, Prometheus and Grafana for metrics, a centralized logging stack (ELK, Loki, or a managed service like Datadog or Axiom). The ability to debug a production incident using traces and metrics is the actual skill, not just knowing how to run the tools.
Cloud. AWS is the most common; GCP and Azure have their niches. Multi-cloud experience sounds good on a resume but often means surface-level exposure to each rather than deep expertise in any. For most teams, deep expertise in one cloud is more useful.
What is becoming more important:
FinOps awareness. Cloud bills have become a material cost at any company running serious workloads. Engineers who understand how to read a cloud bill and what drives costs (egress, data transfer, oversized instances, unused resources) are increasingly valuable.
Supply chain security. SBOM generation, container image scanning (Trivy, Snyk), signing images with Cosign, SLSA compliance. Regulation and customer expectations are pushing this into standard practice.
How to screen a DevOps candidate
The portfolio signal for DevOps is harder to evaluate than software engineering. They may not have public GitHub repos. Look for:
- Documented postmortems or incident reports (many engineers keep anonymized ones)
- Conference talks or blog posts about infrastructure work
- Contributions to open-source infrastructure projects or Helm charts
- Demonstrated certification (AWS Solutions Architect Professional, CKA, CKAD) as a minimum bar signal, not a hiring criterion
For the technical screen, use a scenario, not an algorithm:
“We have a Node.js service running in Kubernetes that is serving elevated p99 latency (around 2 seconds) during business hours. CPU usage is normal. Memory is stable. The service has 3 replicas. Walk me through how you would investigate this.”
A good answer covers: checking pod-level metrics vs node-level metrics, looking at request traces if available, checking for garbage collection pauses in Node.js (heap dumps, GC logs), looking at whether the p99 is caused by a specific endpoint or all of them, checking if the latency correlates with horizontal scaling behavior, and asking about external dependencies (databases, downstream APIs).
A weak answer goes straight to “I would increase the number of replicas” without diagnosing why the latency is elevated.
The infrastructure review. Share a Terraform configuration (can be from a public repo) and ask them to review it. You are looking for:
- Security issues (overly permissive IAM roles, public S3 buckets, hardcoded secrets)
- Missing best practices (no remote state, no locking, no variable validation)
- Whether they structure feedback clearly or just list problems
The “make developers faster” question. “What is the biggest thing you have done that made other developers more productive?” A platform engineer orientation shows up here. Look for: they reduced CI time, they built a self-service deployment tool, they moved a manual process to automation, they wrote a runbook that eliminated a class of support requests. Operations-only engineers answer this with things like “I set up monitoring.” Platform engineers answer with outcomes for other people.
What to pay
| Level | India (annual) | US (annual) | Contract rate |
|---|---|---|---|
| Mid (3-5 yrs) | $30k-$55k | $130k-$170k | $65-$100/hr |
| Senior (5-8 yrs) | $55k-$80k | $170k-$220k | $100-$150/hr |
| Staff / Principal | $80k+ | $220k-$300k | $150+/hr |
| Platform engineer (senior) | $60k-$90k | $180k-$250k | $110-$160/hr |
Senior DevOps engineers with Kubernetes operator development experience, multi-cloud architecture, or SRE background with strong software skills command a premium over these ranges. Expect to compete aggressively for that tier in any market.
A note on scope: if you are hiring one person to do everything (cloud, CI/CD, Kubernetes, on call, FinOps), you are asking for a senior or staff engineer. Do not post that role at mid-level rates and wonder why you get mid-level candidates.
This post is part of the hiring series. For adjacent roles: How to hire a React developer, How to hire a Python developer, How to hire an iOS developer, and the overview of what developers cost across geographies and experience levels.
Frequently asked questions
- What is the difference between a DevOps engineer, a platform engineer, and an SRE?
- DevOps engineer is the oldest title and the broadest — it can mean anything from writing Terraform to managing CI/CD pipelines to being the person who handles on-call. Platform engineer specifically builds internal developer platforms: the tooling, abstractions, and self-service infrastructure that product engineers use. SRE (Site Reliability Engineer) focuses on availability, latency, and production reliability, often with an SLO/error budget framework. In 2026, most companies above 50 engineers have split these into distinct roles.
- What IaC tool should I require in 2026?
- Terraform is the most widely used, and OpenTofu (the open-source fork from 2023) is increasingly common since HashiCorp changed Terraform's license. They are nearly identical to write. For AWS-specific teams, CDK (Cloud Development Kit) is a strong alternative. Pulumi is used in teams that prefer real programming languages over HCL. Don't require one specific tool — require that the candidate has written IaC professionally and understands the principles.
- What should a DevOps candidate know about Kubernetes in 2026?
- Beyond the basics (deployments, services, configmaps, secrets), they should understand resource limits and requests, HPA and VPA for autoscaling, pod disruption budgets, network policies, RBAC, and how to use Helm. Critically: they should be able to diagnose a cluster problem from kubectl output — a crashing pod, a node under memory pressure, a failing deployment rollout. Deploying to Kubernetes is easy. Operating it in production is the actual skill.
- How much does a DevOps engineer cost in 2026?
- In the US, mid-level DevOps engineers run $130k-$180k. Senior engineers with Kubernetes and IaC experience run $170k-$240k. In India, the range is roughly $30k-$80k depending on experience level. Platform engineers and SREs at senior level tend to command a premium over pure DevOps titles — the specialization narrows the pool.
Sponsored
More from this category
More from Business
 R.01
R.01 How to Hire an Engineering Manager in 2026: What to Screen for Beyond a Title
 R.02
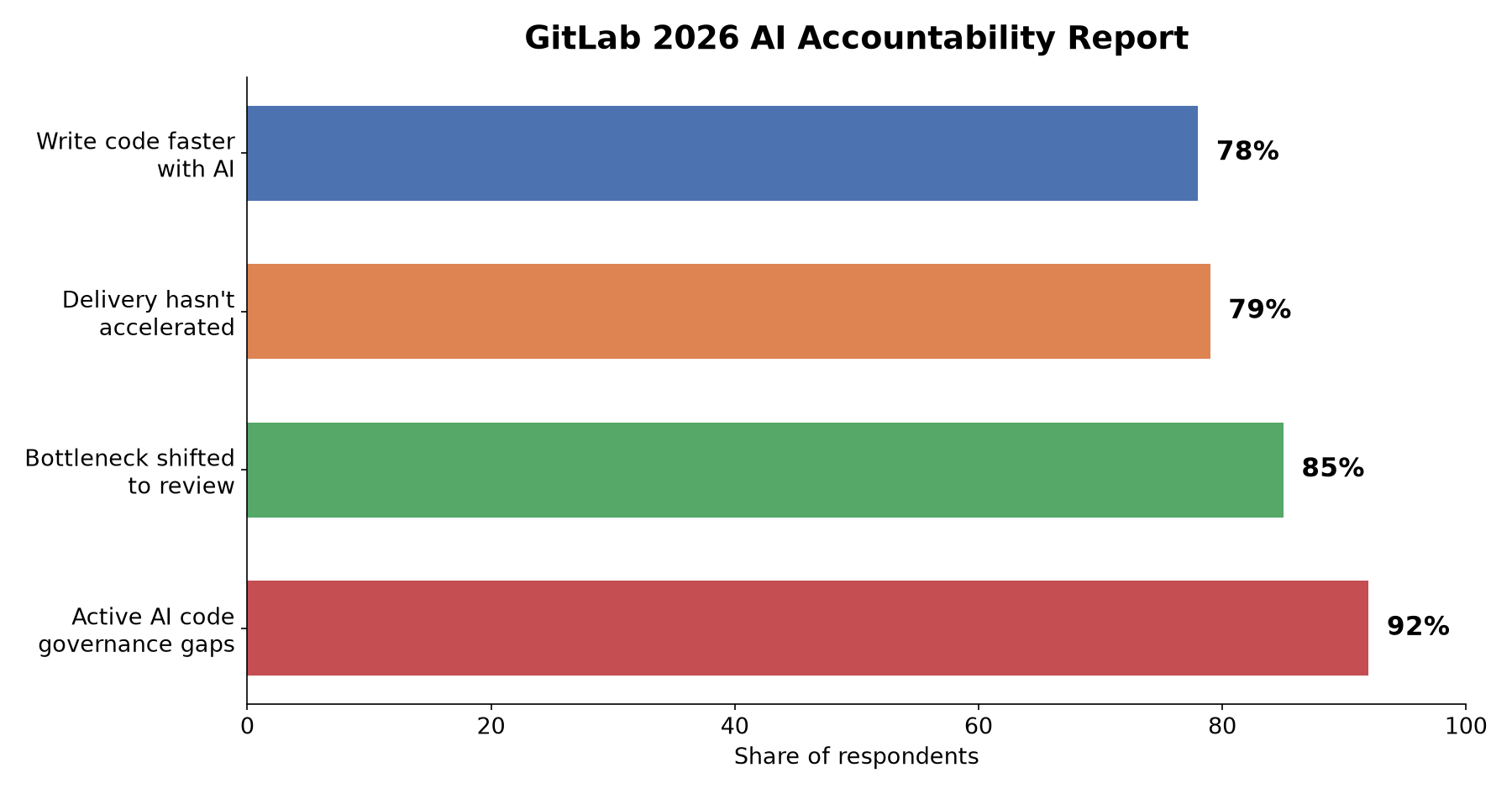
R.02 The AI Paradox: Developers Code Faster, But Delivery Hasn't Sped Up
 R.03
R.03 How to Hire a Game Developer in 2026: Unity, Unreal, and the Screen That Actually Works
Sponsored
Discussion
Join the conversation.
Comments are powered by GitHub Discussions. Sign in with your GitHub account to leave a comment.
Sponsored