AI Integration · Cost Optimization
Reducing LLM API Costs in Production: Caching, Batching, and Model Routing
LLM API bills grow faster than usage. These are the concrete techniques that cut costs by 40-80% without degrading quality: prompt caching, semantic deduplication, tiered model routing, and batch inference.

Prathviraj Singh
9 min read

Sponsored
You shipped the AI feature. Usage is growing. Then the API bill arrives.
LLM costs do not scale linearly with users. They scale with tokens, which means a feature that seemed cheap in development gets expensive fast as usage grows, especially if the system prompt is long, users send verbose inputs, or the model is returning longer completions than you expected.
The good news is that most production LLM systems have significant optimization headroom. The techniques below are not speculative. They are available today on every major provider and can reduce bills by 40-80% without changing what the user sees.
The bad news is that you need to measure before you can optimize. If you do not know which features drive cost and what the token breakdown looks like, start there.
Instrument first
Before any optimization, add logging to every LLM call:
interface LLMCallLog {
feature: string; // which product surface triggered this
model: string;
promptTokens: number;
completionTokens: number;
costUSD: number; // compute from the pricing table at call time
latencyMs: number;
cacheHit: boolean; // fill in once you add caching
requestId: string; // for correlation with provider logs
}Aggregate by feature over 7-day windows. You will usually find that one or two features drive 60-80% of the cost. Those are where you start.
Prompt caching: the highest-leverage change
Prompt caching stores the transformer’s computed key-value pairs for a given input prefix. On subsequent requests that share that prefix, the model reads from cache rather than recomputing, which is faster and costs a fraction of normal input token pricing.
All three major providers support it:
| Provider | Cache read cost | Cache write cost | TTL |
|---|---|---|---|
| Anthropic | 10% of input token price | 25% of input token price | 5 minutes (refreshes on hit) |
| OpenAI | 50% of input token price | Full price (first request) | 5-10 minutes |
| Google Gemini | ~25% of input token price | Full price | 1 hour minimum |
The catch: the cached prefix must be static. System prompts, retrieved documents, conversation history, and other fixed context can be cached. The dynamic user message cannot. Most well-structured prompts have a large system prompt and a small user turn, which means caching dramatically reduces the per-request input cost.
On Anthropic, you mark cacheable prefixes explicitly with a cache_control header:
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[
{
"type": "text",
"text": LONG_SYSTEM_PROMPT, # could be thousands of tokens
"cache_control": {"type": "ephemeral"}
}
],
messages=[
{"role": "user", "content": user_message}
]
)
# Check the usage to confirm cache behavior
print(response.usage.cache_read_input_tokens) # tokens served from cache
print(response.usage.cache_creation_input_tokens) # tokens written to cacheOn a system prompt of 2,000 tokens with 100 daily users each sending 10 messages, moving from no caching to cached system prompt reduces input token cost by roughly 90%. At claude-sonnet-4-6 pricing, that is a meaningful number by month’s end.
Semantic caching for repeated questions
Prompt caching handles identical prefixes. Semantic caching handles near-duplicate user inputs.
Users ask the same question in different words constantly, especially in support, Q&A, and document retrieval features. “What is your return policy?” and “How do returns work?” are different strings that should return the same response. Without semantic caching, both hit the API and pay full price.
Semantic caching works like this: embed the incoming user query, compare it against a vector index of cached (query, response) pairs, return the cached response if similarity exceeds a threshold (typically 0.92-0.95 cosine similarity), and cache the new pair if it misses.
A minimal implementation with Redis and pgvector:
import psycopg2
import numpy as np
from openai import OpenAI
client = OpenAI()
conn = psycopg2.connect(DATABASE_URL)
SIMILARITY_THRESHOLD = 0.93
def embed(text: str) -> list[float]:
return client.embeddings.create(
input=text,
model="text-embedding-3-small"
).data[0].embedding
def semantic_cache_get(query: str) -> str | None:
embedding = embed(query)
cur = conn.cursor()
cur.execute("""
SELECT response, 1 - (embedding <=> %s::vector) AS similarity
FROM llm_cache
ORDER BY similarity DESC
LIMIT 1
""", (embedding,))
row = cur.fetchone()
if row and row[1] >= SIMILARITY_THRESHOLD:
return row[0]
return None
def semantic_cache_set(query: str, response: str):
embedding = embed(query)
cur = conn.cursor()
cur.execute("""
INSERT INTO llm_cache (query, response, embedding)
VALUES (%s, %s, %s::vector)
ON CONFLICT DO NOTHING
""", (query, response, embedding))
conn.commit()Cache hit rates after the first week of operation are typically 30-60% for customer-facing features. The embedding call itself costs a small amount, but text-embedding-3-small at $0.02 per million tokens is trivially cheap compared to a full generation call.
One caution: staleness. A cached response that is weeks old may be wrong if the product changed. Include a TTL and an invalidation mechanism for content that changes.
Model routing: right model for the task
Not every request needs your most capable model. A classification task, a short factual lookup, or a simple reformatting job does not need GPT-4 or Claude Opus. It needs something that is correct and fast.
Model routing classifies incoming requests and sends them to the cheapest model that can handle them:
from enum import Enum
class RequestComplexity(Enum):
SIMPLE = "simple" # factual lookup, classification, formatting
MEDIUM = "medium" # summarization, basic Q&A, code completion
COMPLEX = "complex" # reasoning, long-form writing, code generation
MODEL_BY_COMPLEXITY = {
RequestComplexity.SIMPLE: "claude-haiku-4-5-20251001",
RequestComplexity.MEDIUM: "claude-sonnet-4-6",
RequestComplexity.COMPLEX: "claude-sonnet-4-6", # or claude-opus-4-8 for highest stakes
}
def classify_complexity(user_message: str, context: dict) -> RequestComplexity:
# Rule-based is often good enough to start
if len(user_message) < 100 and context.get("task_type") in ("classify", "format", "extract"):
return RequestComplexity.SIMPLE
if context.get("requires_reasoning") or len(user_message) > 1000:
return RequestComplexity.COMPLEX
return RequestComplexity.MEDIUM
def route_request(user_message: str, context: dict) -> str:
complexity = classify_complexity(user_message, context)
return MODEL_BY_COMPLEXITY[complexity]The cost differences are large. Haiku 4.5 is roughly 20-30x cheaper than Opus 4.8 per token. Even moving 40% of requests from Sonnet to Haiku reduces the blended cost by 20-30%.
The risk is misrouting: sending a complex task to a cheap model and getting a wrong or low-quality response. The mitigation is to start conservative (route only very clearly simple tasks to the cheap model), track quality metrics per model tier, and expand routing as you gain confidence in the classifier.
Existing tools like OpenRouter and LiteLLM have routing built in and support fallbacks when a model is unavailable.
Batch inference for offline workloads
Any task that does not need a real-time response is a candidate for batch inference. The savings are significant and the implementation is simple.
Anthropic’s Batch API and OpenAI’s Batch API both offer 50% cost reduction on batch requests, processed within 24 hours. Google Vertex has similar offerings.
import anthropic
client = anthropic.Anthropic()
# Create a batch for document summarization
batch = client.messages.batches.create(
requests=[
{
"custom_id": f"doc-{i}",
"params": {
"model": "claude-sonnet-4-6",
"max_tokens": 500,
"messages": [
{"role": "user", "content": f"Summarize this document:\n\n{doc}"}
]
}
}
for i, doc in enumerate(documents)
]
)
print(f"Batch ID: {batch.id}")
# Poll for completion or use a webhookUse cases that map well to batch inference: content classification at scale, document summarization pipelines, bulk data extraction, generating product descriptions, batch translation, and any nightly data processing job.
Tasks that do not fit: anything user-facing that needs a response within seconds.
Output token reduction: where the money hides
Input tokens are cheaper than output tokens on every major provider. Long, verbose completions cost more than short, direct ones, and they are slower.
The practical lever is explicit instructions in the system prompt:
Be concise. Use bullet points instead of prose for lists. Do not restate the user's question.
Limit responses to 300 words unless the task genuinely requires more.On customer-facing features, reducing average completion length from 400 tokens to 150 tokens cuts output cost by 62%. Check your analytics: if the median user reads 150 tokens of a 400-token response, the extra 250 tokens are cost with no value.
For structured data extraction, use JSON output modes (supported on all major providers) rather than asking the model to explain its reasoning first. Structured output produces shorter completions and is easier to parse downstream.
Putting it together
The order of operations matters. Each of these techniques takes time to implement correctly. A reasonable sequencing:
- Instrument (one sprint): log model, tokens, cost, latency for every call. No optimization yet.
- Identify the hot paths (one week of data): which features drive 80% of cost?
- Add prompt caching (one sprint): highest leverage, lowest risk, lowest complexity.
- Add model routing for clearly simple tasks (one sprint): conservative routing on well-understood request types.
- Add semantic caching for high-volume Q&A features (one to two sprints): more complex, higher reward for the right use cases.
- Move eligible offline work to batch (one sprint): straightforward if the feature is already async.
- Tune output length (ongoing): iterative, based on real usage data.
Most teams that go through this sequence find that steps 3 and 4 alone cut their bill by 40-60%. Steps 5 and 6 can take it further.
The budget lines that tend to catch teams off guard during AI feature development are covered in what an AI feature actually costs. For observability tooling that makes cost tracking less painful, LLM observability tools covers the options. If you are building AI features for clients and need to explain these cost structures in project scoping, the context is useful for how we structure AI integration projects.
One thing to track that most teams do not
Track cost per unit of user value, not just cost per call.
A feature where each LLM call generates a report that saves a user 30 minutes has a very different economics profile than a feature where each call produces a one-line summary the user ignores. The second feature looks cheap per call but has no return. The first looks expensive but is worth every token.
The optimization work makes more sense, and is easier to prioritize internally, when it is connected to the value the feature delivers. A 50% cost reduction on a feature that should not exist is not an accomplishment.
Frequently asked questions
- What is prompt caching and how does it work?
- Prompt caching stores the computed key-value pairs from the transformer's attention mechanism for a given input prefix. When the same prefix appears in a subsequent request, the model skips recomputing it and reads from cache instead. This is faster and cheaper. Anthropic charges 10% of the input token cost for cache reads (vs full price for cache misses), and Google Gemini offers similar pricing. The prefix that qualifies for caching is typically the system prompt and any fixed context, not the dynamic user message.
- What is semantic caching?
- Semantic caching stores LLM responses and retrieves them when a new input is semantically similar (not just identical) to a cached query. It uses embedding models to compute similarity between the incoming query and cached queries, then returns the cached response if the similarity is above a threshold. Redis with a vector index or a purpose-built tool like GPTCache handles this. It is most valuable for Q&A, support bots, and RAG systems where users ask the same question in different words.
- How does model routing work in practice?
- Model routing classifies each incoming request and sends it to the most cost-effective model that can handle it. A classification request or a short factual lookup goes to a small, cheap model. A complex reasoning task or a request requiring nuanced writing goes to a large model. The router can be a separate classifier model, a rule-based system, or a lightweight ML model trained on your own data. OpenRouter and LiteLLM both have routing built in.
- Is batch inference worth the latency tradeoff?
- Yes, for offline workloads. Anthropic's Batch API, OpenAI's Batch API, and equivalent offerings on other providers cut per-token costs by 50% in exchange for 24-hour or longer response windows. For document summarization, content classification, data extraction, or any task where the result is not needed immediately, batch inference is straightforward to implement and the savings are significant.
- What should I instrument before optimizing LLM costs?
- At minimum: model name, prompt tokens, completion tokens, total cost per call, latency, and whether the response came from cache. Aggregate this by feature (which product surface triggered the call), by user cohort if relevant, and over time. You need to know which features drive cost and what the cost per unit of value is before you can prioritize optimizations.
Sources
Sponsored
More from this category
More from AI Integration
 R.01
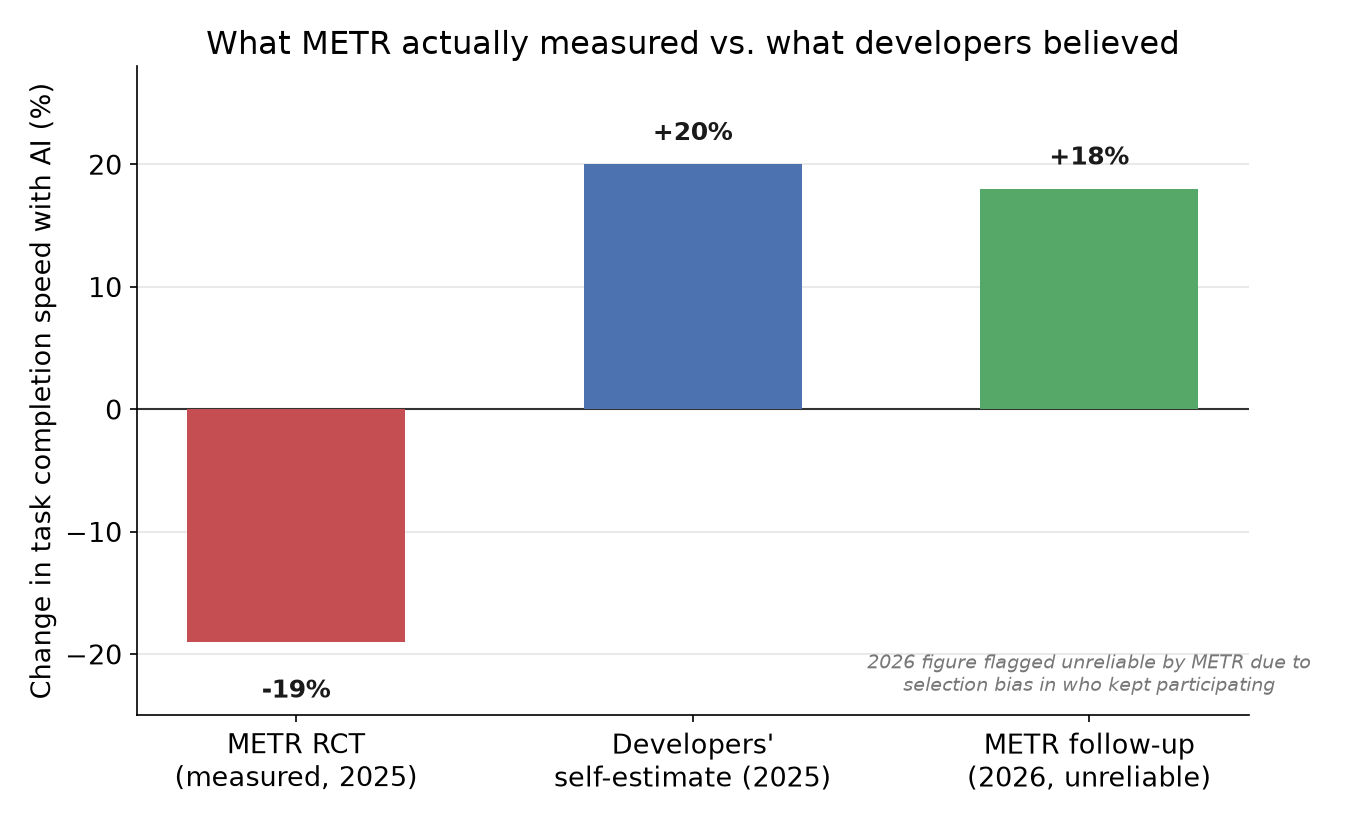
R.01 AI Didn't Make You 10x Faster at Coding. Here's What the Data Actually Shows
 R.02
R.02 GPT-Live-1 Is Out. If You're Building a Voice App Today, Don't Wait For It
 R.03
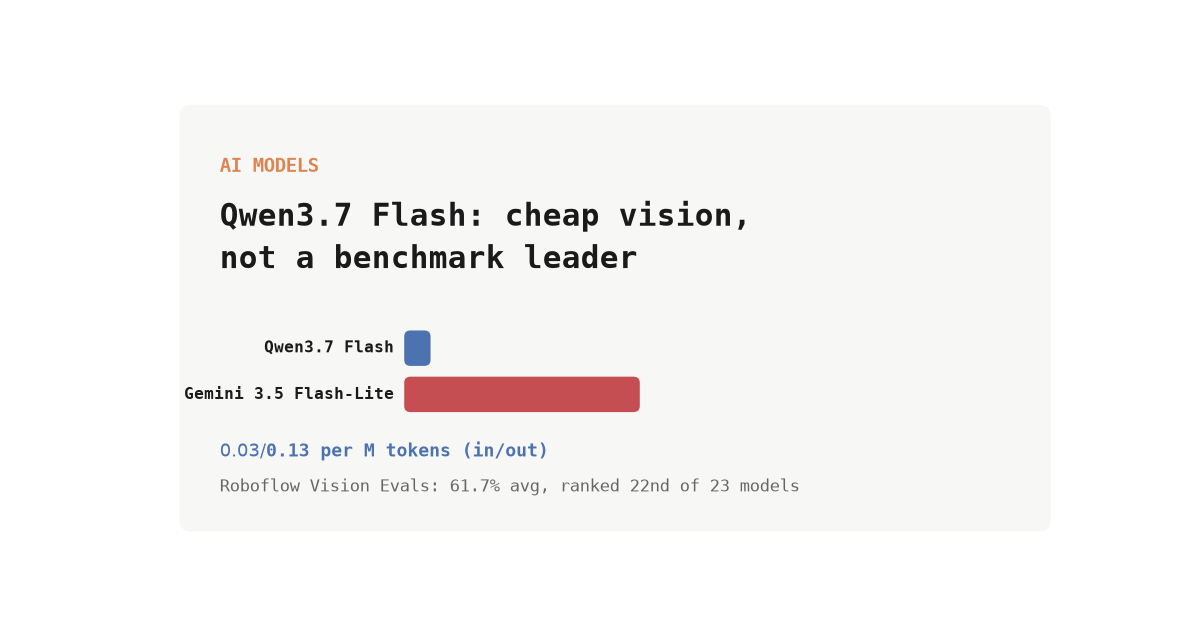
R.03 Qwen3.7 Flash: Alibaba's Dirt-Cheap Vision Model Lands on OpenRouter
Sponsored
Discussion
Join the conversation.
Comments are powered by GitHub Discussions. Sign in with your GitHub account to leave a comment.
Sponsored